Markdown Rendering and Recursive Composition
Have you ever thought about how this article is rendered on your screen? We all know about fonts, font sizes, bold/italic/underlined styling, paragraphs, bullet points but have you ever actually thought about the steps behind this process? A part of the text can be bold or italic but where is that information stored? Although there is no indicator in the text itself, this statement reminds us one of our favorite markup languages.
You are most likely familiar with Markdown which sits as a bridge between the two worlds of formatted and plain text. It lets you stylize your text in a plain text editor and any compatible renderer would turn it into a nice stylized document. Github README files, slack chat messages, Reddit comments, all support a version of Markdown. Although WYISWYG editors usually output documents in XML or JSON formats which are adapt for machine readability, Markdown is advantageous in terms of being human readable without much distraction.
In this post I want to solely focus on how Markdown helps with converting a styleable text into plain text as well as how would a UI framework like Compose go on to covert that plain text into a beautiful looking, styled document.
Markdown Parsing
Markdown documents are not pre-processed, meaning that they are written, storred, and transferred as they are. A Markdown Renderer receives the plain text content directly. Then, the renderer would be responsible for converting the text into a structured document. For the rest of this section, I’ll be basing the parsing on Commonmark library.
Hello, **World!**
Above text is an obvious one for Markdown readable people. However, it is not instantaneously apparent for a word processor to understand what those (*) stars mean. An intermediate renderer must know all the Markdown rules to interpret the text in a structured way for a text renderer to stylize it. When this text is given to Commommark parser, output looks like the following

We can of course go further and mix it up a bit
Hello, **Wo_rld_!**
Then, this would correspond to

We are starting to get a hang of how a text block is stylized internally. Bold, Italic, Strikethrough, Underline, Link, inline images, and etc. would all follow the same approach when applied. On the other hand, paragraph is not an inline style but considered as a text block. Text blocks include but not limited to; bullet points, code blocks, quotes, and numbered lists. Lastly, let’s add a bullet point to our example before moving on with the data structure behind the parsed result.
Hello,
- **Wo_rld_!**

Finally, we have 2 text blocks where one of those also includes inline styling.
So, the last question is how would a parser output its result? It actually depends on what the consumer is going to do with it. If we are only thinking about parsing and storing the result for future use, the output can be a JSON or XML that resembles an HTML document. However, Commonmark is a multi-purpose parser that is available in different languages. We will be talking about the Java version. It would be wasteful to get JSON or XML as an output because they would need to be further parsed to be used in whatever UI framework we are working in. Instead, Commonmark gives us a tree which is not very surprising. Looking at the last example, we can easily imagine it as a tree
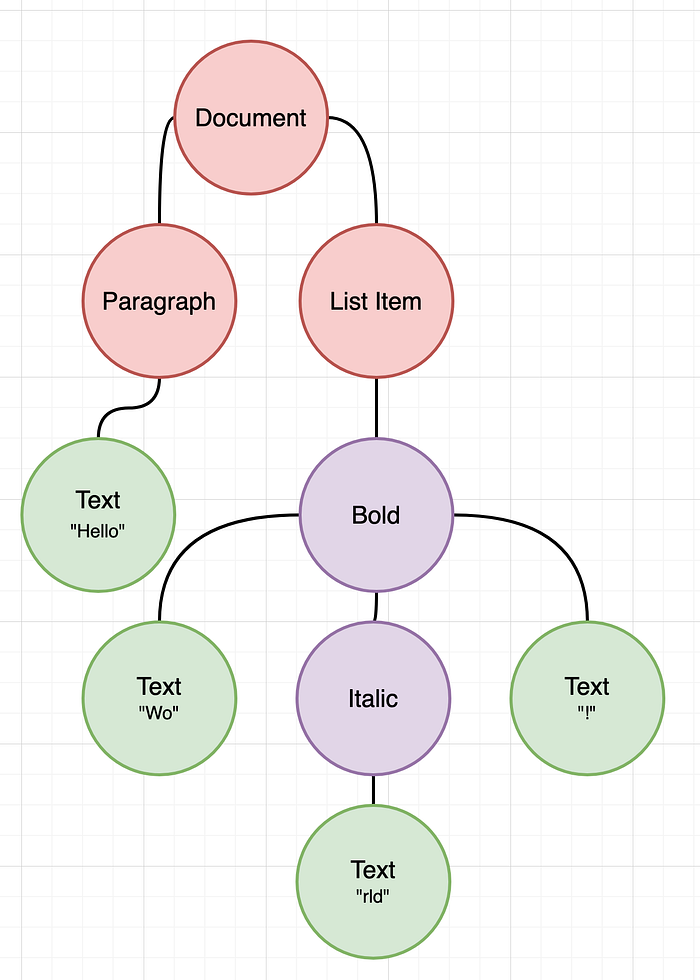
Although it looks convoluted, this tree is very easy to reason about. It starts with a Document tag at the root. Its children are expected to be blocks that contain Text. First paragraph has a single child that says “Hello” without any styling, pretty simple. Second child declares itself to be a list item so we assume that there is going to be a bullet point at the left side of this block. Only child under it is of a styling nature. “Bold” tree node declares that all of its children need to be stylized with Bold rule. So, “Wo”, whatever under “Italic”, and “!” are all need to be bold. Same situation applies to the children of “Italic” node, meaning that “rld” is going to be both Bold and Italic.
Trees, Recursion, Traversal
Anyone who has spent sometime with any UI framework would tell you that all UI is actually a tree of components. Compose is no different and actually makes it quite apparent. Even further, Compose is split into two parts in which an abstract dynamic tree is updated with the latest state and the other part spits out UI according to the changes in this tree. Here are a few resources for curious ones to learn more
Our Markdown tree from earlier aligns very well with Compose. The only thing we need to do is traverse the tree while emitting corresponding Composables. This correspondence can be quite simple as in we should have Composables for text blocks which accept a content parameter that would include children. I haven’t mentioned this yet but text blocks can include other text blocks in a Markdown spec.
Let’s start with some code examples
This gist shows what kind of composable tree we are expecting for our Markdown example. Function names and call order is completely arbitrary at this point. We are going to use compose-richtext library for building blocks later on. For now, our attention should be on how to traverse a parsed Markdown Tree while emitting Composables.
Axioms are useful while working on complex systems to define some boundaries. Hence, it’s a good idea to determine those axioms at the beginning for a solid implementation plan.
- Every document starts with a Document node.
- Text and styling nodes reside always under a text block e.g. Paragraph, Quote, ListItem, etc.
- Text is a terminal node. Text cannot have children.
- Styling does not leak to other text blocks. Style nodes cannot have text block as children.
- All Text Blocks must have Paragraph as their first child e.g. BlockQuote -> Paragraph -> Content
A generic view of a Markdown node is as follows:
Node:
- leftChild
- rightChild
- next
- previousIn our example, we will also have a children iterable that goes from the most left child to the most right.
It’s quite predictable that recursively traversing this tree while emitting Text Block composables would be the way to go. An almost pseudo code for that is given below
Node is supposed to be a sealed class that has subtypes of all the defined text blocks under our Markdown documentation. Given that we have iteration helpers and text blocks that are available from compose-richtext, it looks almost too easy. It is nearly enough to call render from root node and the rest should work out. Unfortunately, text inside a paragraph might be defined as a tree but cannot computed in a recursive way. Please refer to the first code example where Text blocks are called separately. Compose is going to treat those text calls as separate Text composables, therefore the output would actually be series of independent Text layouts.
Instead, our axioms tell us that once we encounter a Paragraph, we can safely assume the rest of the children are going to be either Text or styling nodes. From there on out, we can compute a stylized text block that is undividable.
Although recursion does not work, we can do a pre-order traversal while building a spanned text. The complete code for this process can be found here
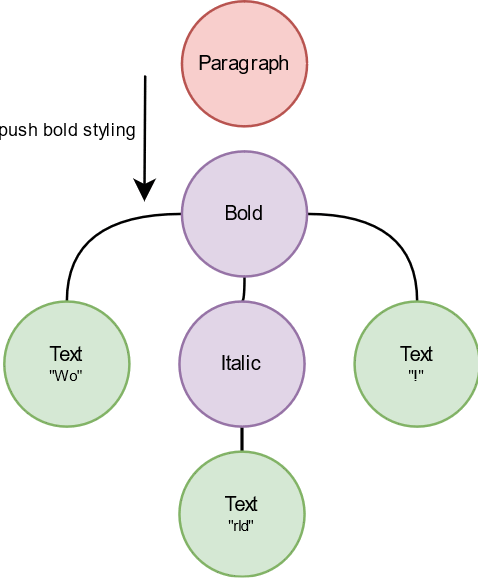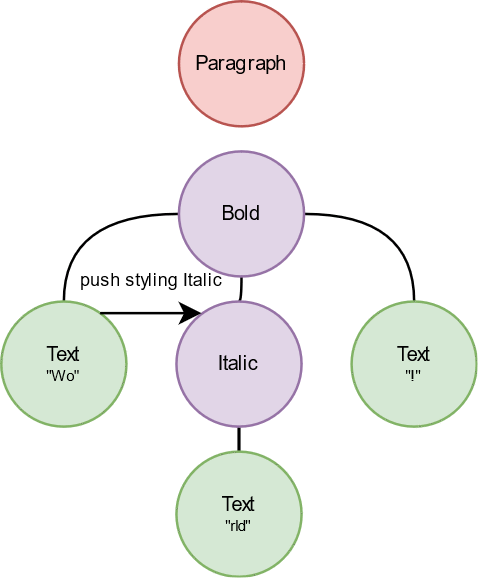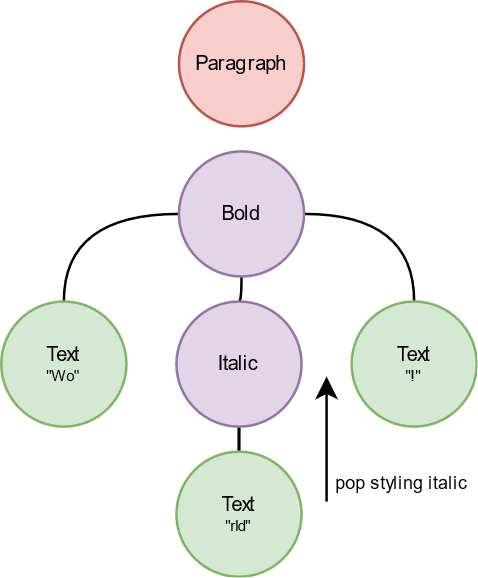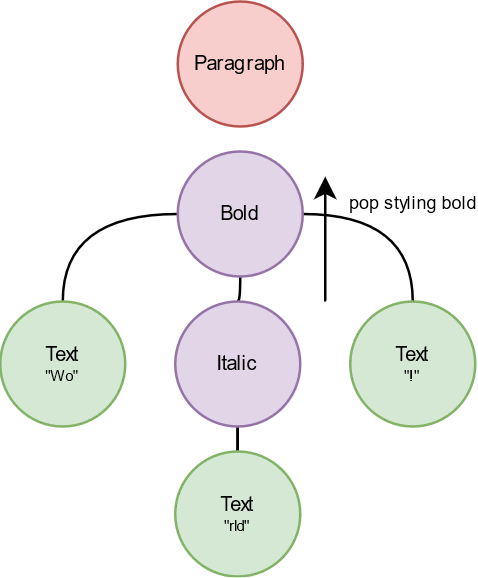
Pre-order traversal for building a spanned string is explained in the gif above. Styling nodes push a span into ongoing builder, text nodes append their content to the builder. In the end, a spanned, or a RichText, is ready to be called with a single Text node. For the rest, we can continue with the recursive method.
Conclusion
I must admit I skipped tons of steps while trying to simplify this topic. Anyone who I got their attention and might have lit a spark in their interest towards this kind of topic can check out the whole compose-richtext library.
The complete implementation of this Markdown renderer can be found below richtext-commonmark module. It’s a very rough implementation so contributions are welcome.

